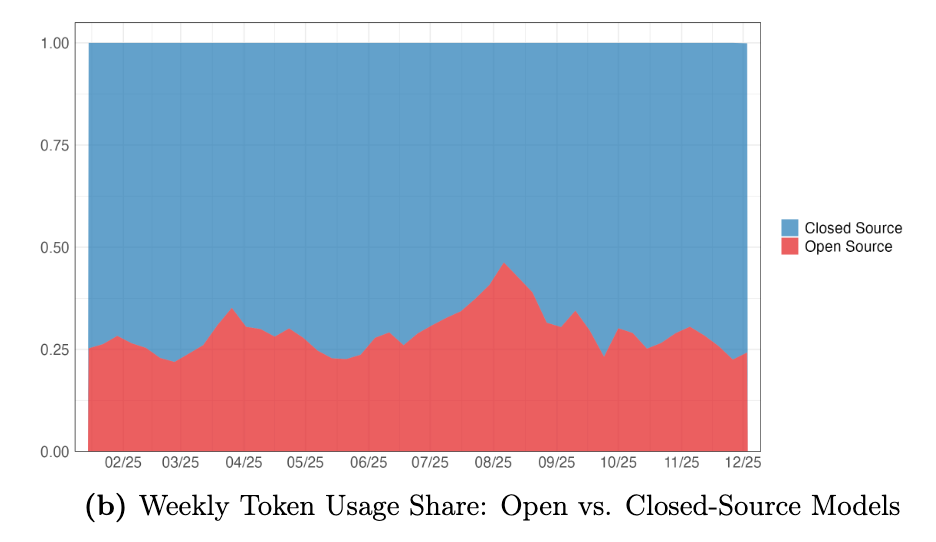
Open source LLMs are 90% cheaper than closed source models at the same benchmarked intelligence level. Yet they capture less than 30% of token share.
If intelligence were all that users cared about, price competition should have closed this gap by now. It hasn't.
Open source's share of token volume on OpenRouter, the leading LLM aggregator, has been stable at 30% for some time, despite all the shifts in the broader market. They even go so far as to call this an "equilibrium."
Standard economic intuition says that, at the same quality level, the cheaper option should win. The LLM market seems to violate this. Something else must be going on.
This puzzle has a precise analogue in economic theory – latent demand. And rather than AI researchers, it's economists and finance researchers who have the most to say about it.
Join the Syndicate
Long-form essays on the economics of tech, with the data to back it up. All signal, no noise.
Read by 5,000+ founders, engineers, and investors.
Priceless
A group of economists from MIT, Boston University, and Microsoft recently published an empirical study of LLM market dynamics, what they call "The Emerging Market for Intelligence.”
The irony of that title: the paper's results suggest consumers of LLM APIs care about far more than mere intelligence:
… open-source models are approximately 90% cheaper than closed-source models, conditional on the same level of intelligence… Nonetheless, the share of tokens consumed from open-source models remains consistently below 30%, suggesting meaningful differentiation between open and closed-source models not captured by intelligence measures – The Emerging Market for Intelligence: Pricing, Supply, and Demand for LLMs
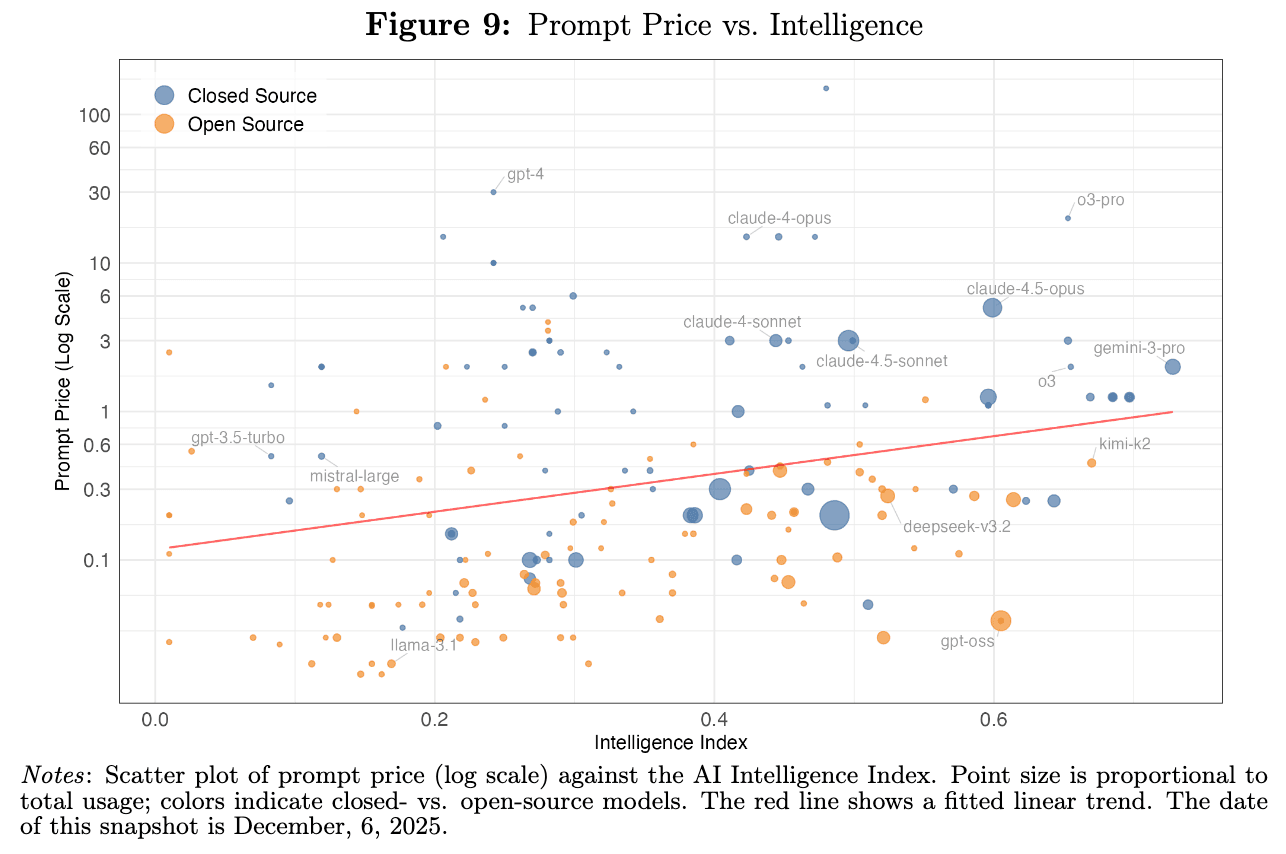
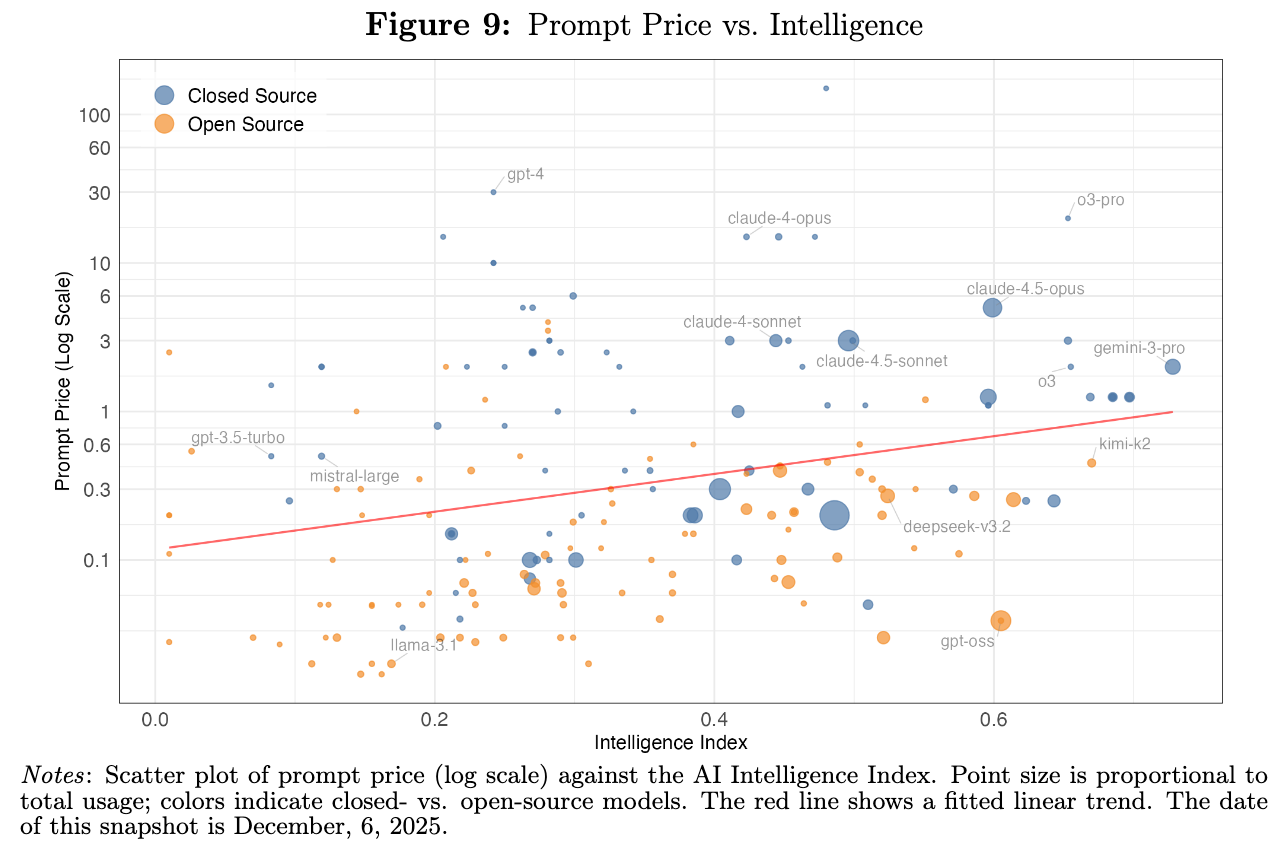
Intelligence only explains so much. You can see it visually here, where open source models at any given level of intelligence are consistently cheaper:
Not just that, but there's incredibly wide dispersion in prices at every level of intelligence. In fact, prices vary by up to two orders of magnitude, and models that are much more expensive relative to their benchmark performance still see substantial use.
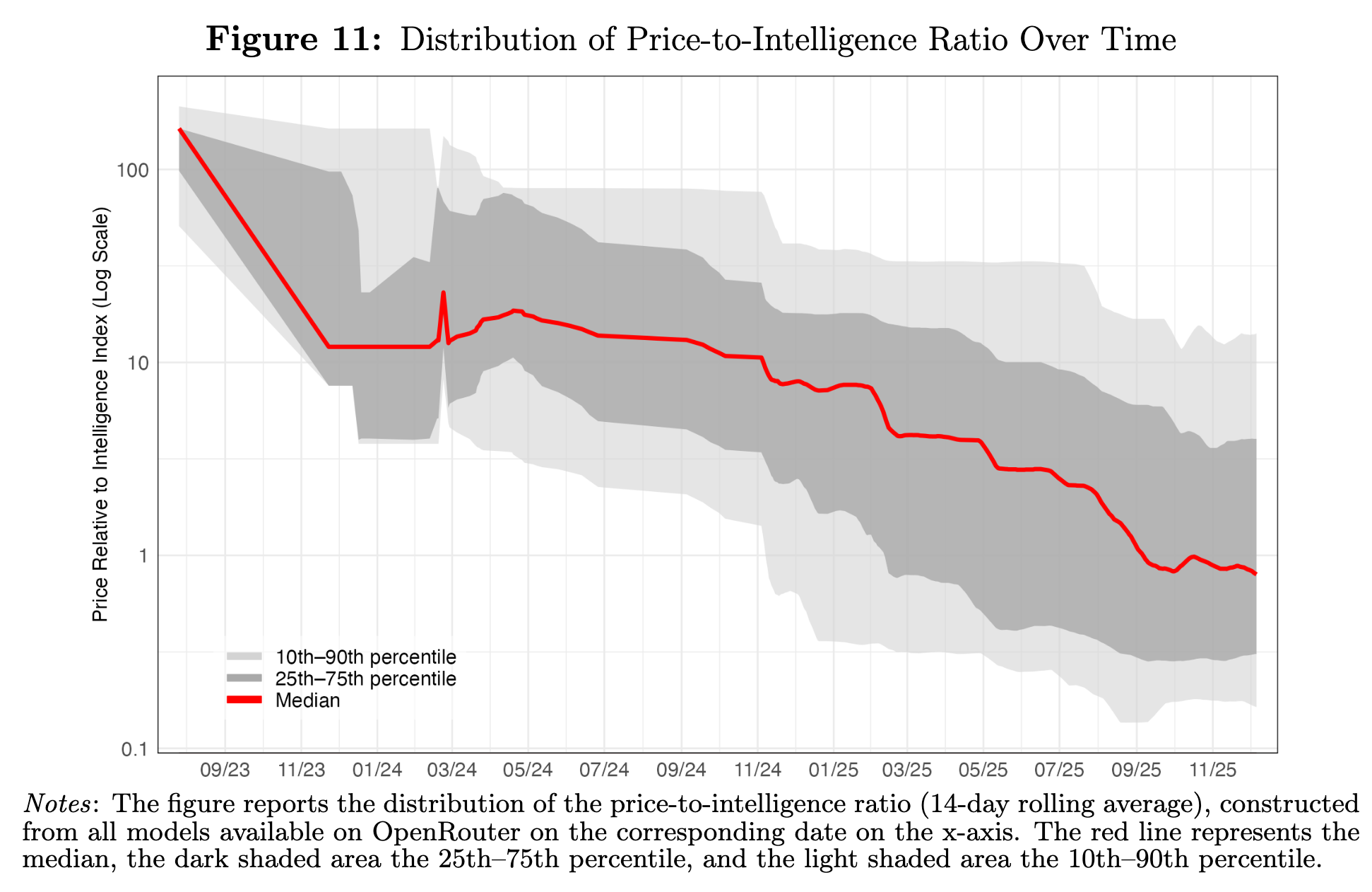
That dispersion of pricing has only gotten more severe over time despite prices falling overall. The price-to-intelligence ratio, which you can think of as representing a measure of quality-adjusted token pricing, has become more dispersed over time:
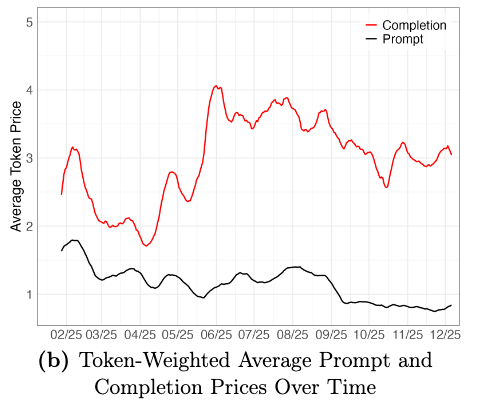
More price puzzles: the average price actually paid for tokens (as opposed to simply the average or median list price) increased over the course of 2025. This seems to have been completely missed in the discourse last year and is strong evidence that price is not a primary motivating factor for many users:
A reasonable hypothesis is that the observed run up in token-weighted prices for output tokens was driven by the release of the Claude 4 models in May 2025. This occurred during a period where, per the prior chart, intelligence-adjusted prices were falling through the ground. This is a powerful argument for revealed preference of users, who migrated toward premium models to pay for something benchmarks don’t fully capture.
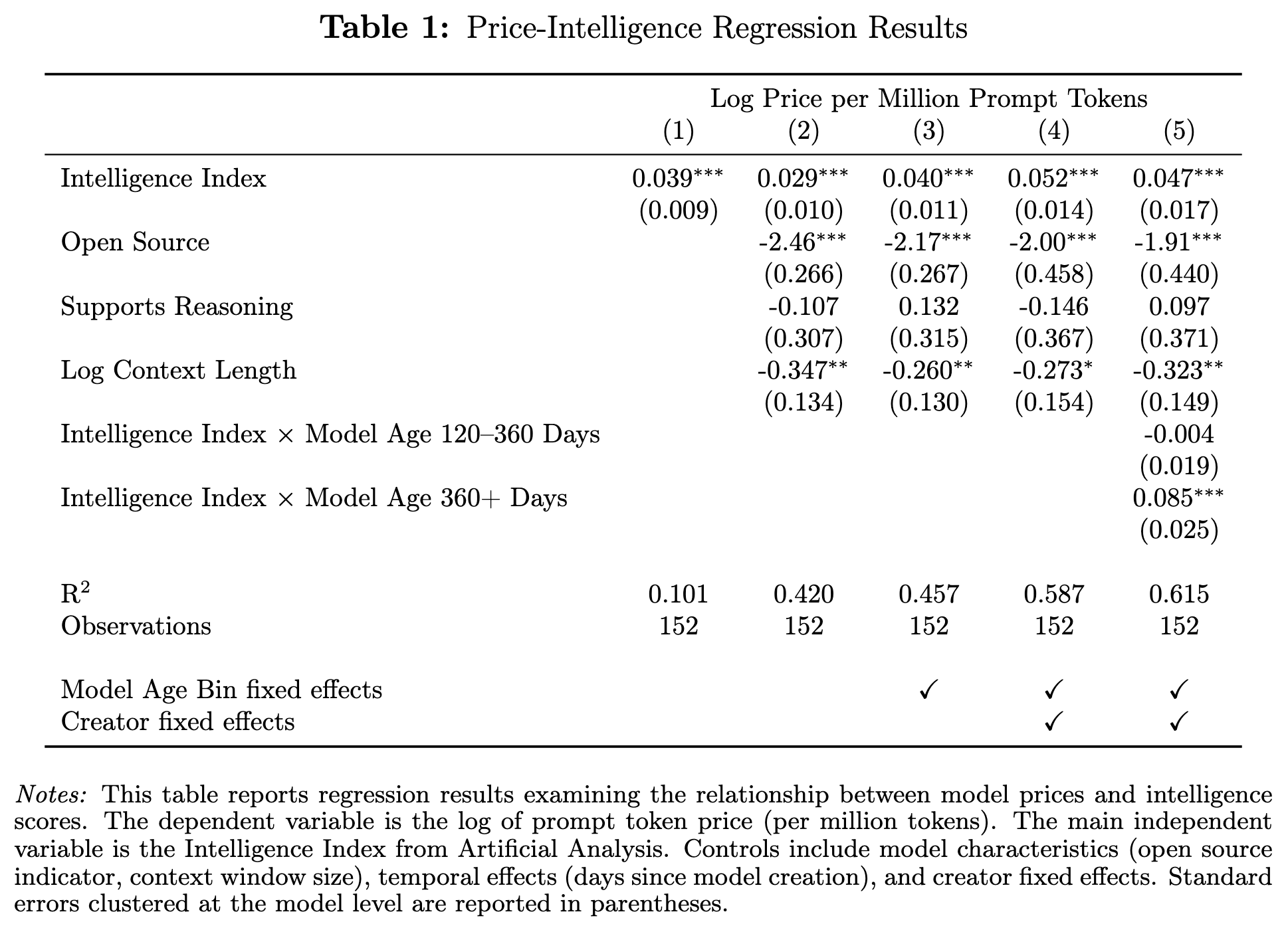
The authors conduct a series of regression analyses across about 150 model-provider combinations to further dig into the drivers of pricing across models, controlling for intelligence, being open source, reasoning capabilities, context length, and other factors. Immediately we can see a few interesting phenomena:
Intelligence alone doesn't determine pricing: the of a simple regression of token price on benchmarked intelligence is only 10%
Age is just a number: adding in controls for the age of a given model doesn't explain much variation in pricing, only increasing the by ~4% over and above the baseline controls. Surprisingly, there's no guaranteed obsolescence here
Brand matters, even more so than intelligence: Adding in controls for the model creator bumps up by 13%, even after including many other controls, explaining more pricing variance than intelligence alone
In total, intelligence clearly matters but it's far from being the only relevant pricing factor.
Volume control
That's pricing, what about quantities? Here too we find a complex picture with no simple answers.
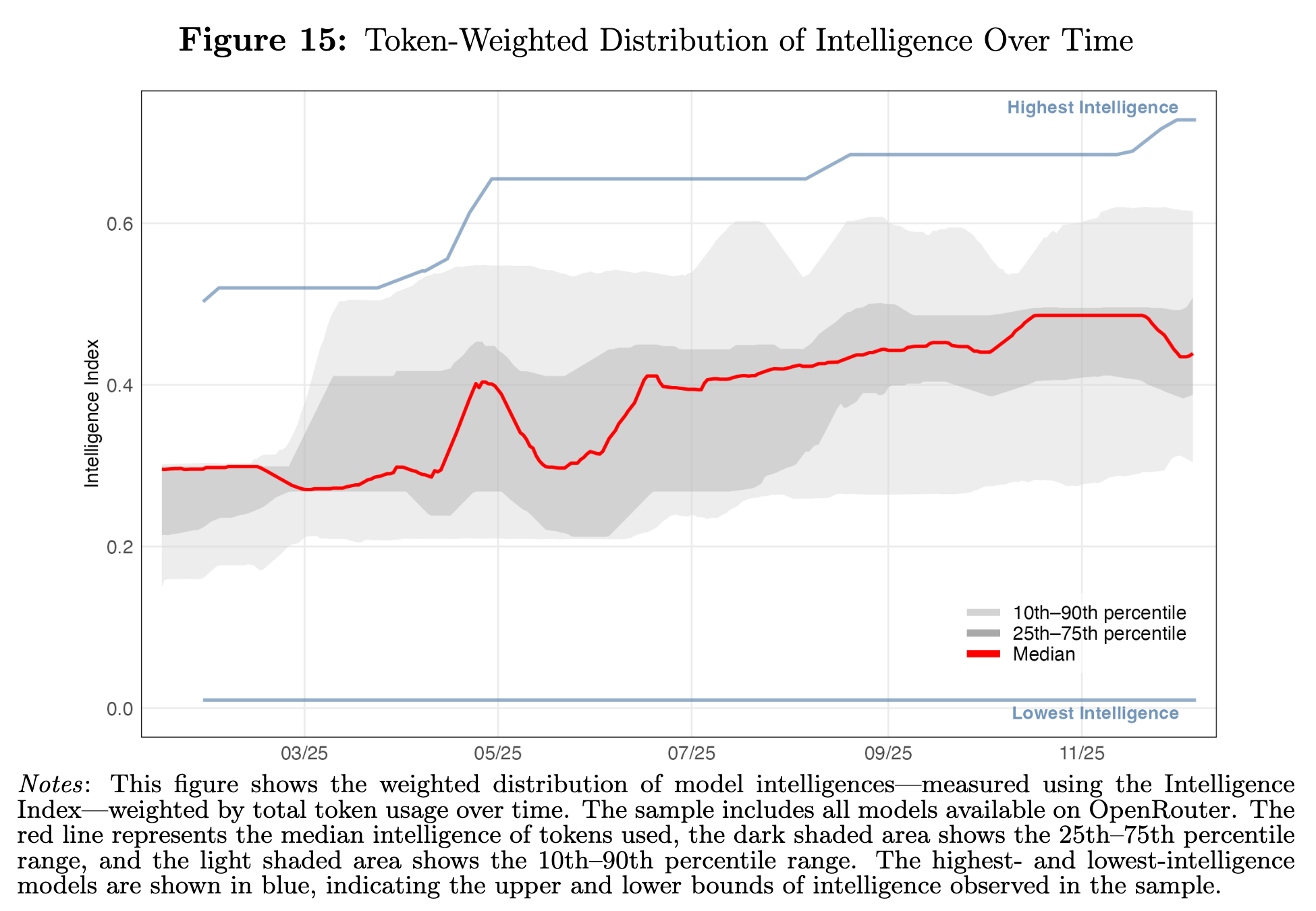
Again, intelligence is not destiny – LLM customers are making decisions based on many factors. If you weight intelligence over time by the actual token usage of those models on OpenRouter, what you see is that typical usage concentrates far from the frontier of intelligence. The median user isn't using anything close to the smartest model, and even the 90% percentile token is coming from a model that is well below the best available:
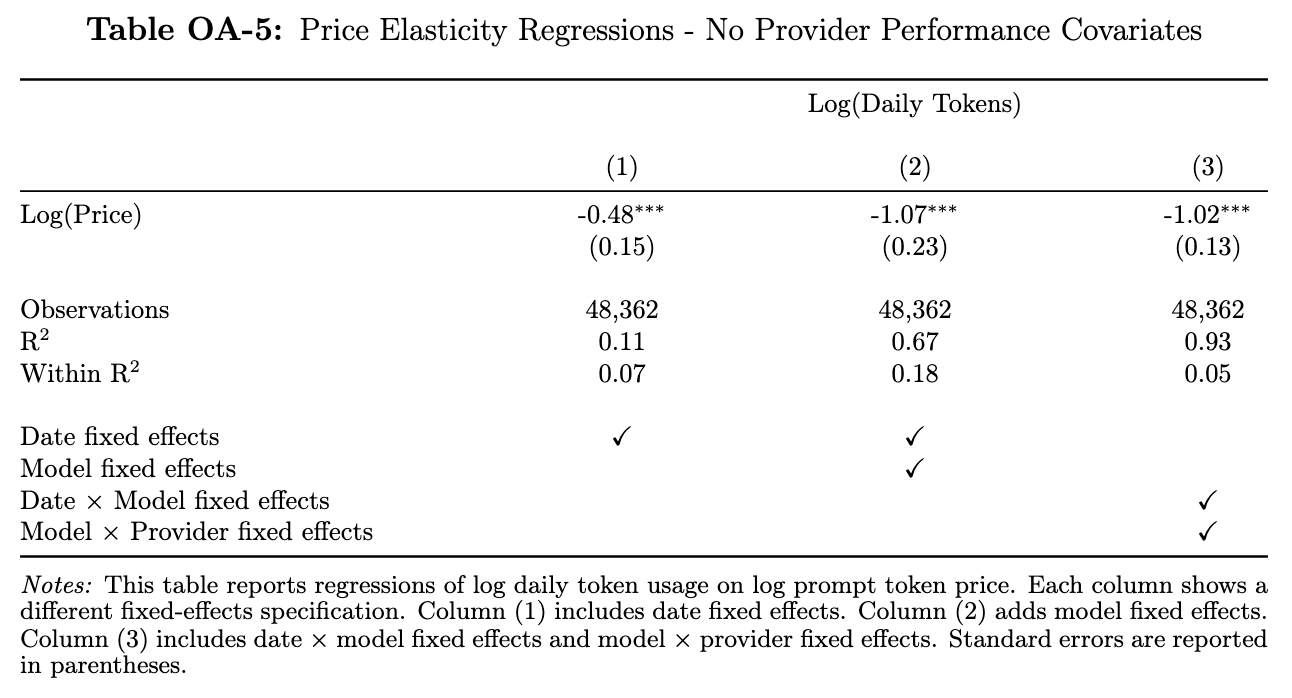
Some more regressions, this time with token volume as the dependent variable.
Pricing matters but only so much: Prices have a statistically significant relationship with token demand, but within a given model, prices explain only 18% of the variance in token volumes. The remaining 82% is driven by other factors
Price competition is zero-sum: The price elasticity of demand is almost exactly one, meaning a 10% price cut generates roughly 10% more volume, leaving revenue (price times quantity) unchanged. To grow revenue, providers must shift the demand curve itself through alternative means
HODL the model: Within a given model/provider combination (rightmost column), price is again statistically significant but explains almost nothing (within of 5%). Most of the action is in the discrete choice of which provider to use in the first place, which is driven largely by factors other than price
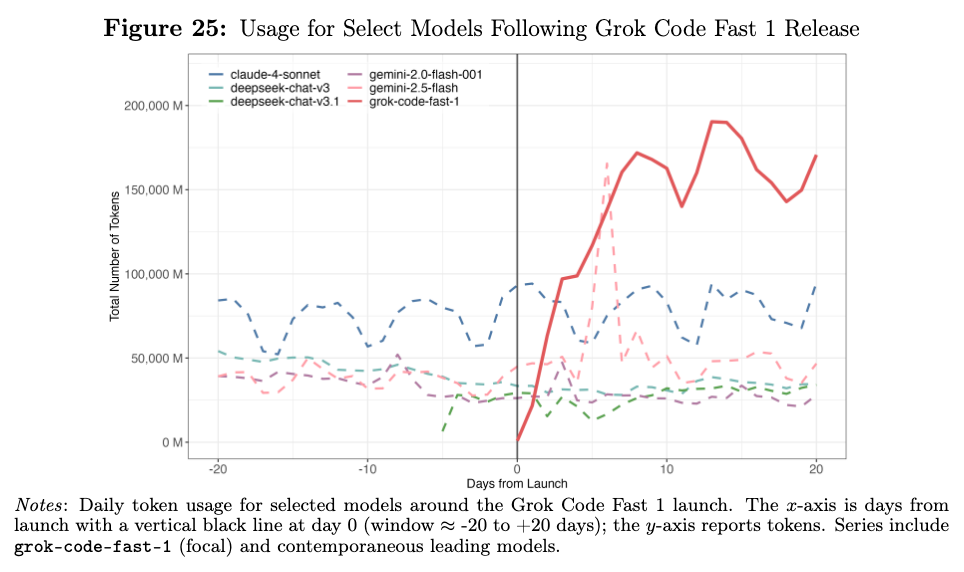
We saw a drastic example of this phenomenon during the release of Grok Code Fast 1, xAI’s extremely fast and cheap coding model, with heavily subsidized pricing (even as low as free). Grok Code Fast 1’s release had zero impact on the demand for other models, suggesting more nuanced user preferences not easily swayed by cost:
The pattern on the quantity side mirrors what we saw with pricing. Intelligence alone explains little price variation; price alone explains little quantity variation. In both cases, the observable characteristics we fixate on (benchmark scores, token prices) leave most of the picture unexplained.
Users don’t always pick the smartest model, and they aren't purely chasing the lowest price. Something else is guiding their choices.
Latent space demand
The asset pricing literature has developed precise tools for exactly this kind of problem. In “A Demand System Approach to Asset Pricing” Koijen and Yogo construct and estimate a “demand system” for public equities. They decompose demand for a given stock into two components, demand driven by observable characteristics (price, profitability, book equity, dividends, etc.) and demand driven by what they call latent demand -- investor preferences for attributes we cannot observe.
We refer to as latent demand, which captures investor 's demand for unobserved (by the econometrician) characteristics of asset – A Demand System Approach to Asset Pricing
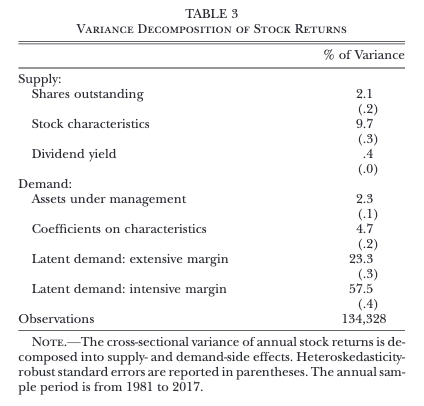
When they apply this framework to the data on U.S. stock returns, they find something striking -- observable characteristics on both the supply and demand side only explain ~20% of the cross-sectional variance of returns. The remaining 80% is dark matter -- driven by unobservable, latent demand among investors:
Thus, stock returns are mostly explained by demand shocks that are unrelated to changes in observed characteristics. This finding is consistent with the fact that cross-sectional regressions of stock returns on characteristics have low explanatory power
Koijen and Yogo are careful to point out that they cannot directly identify what latent demand contains (by definition); they can only quantify how much it matters. Some of their hypothesized drivers: structural constraints (certain investors cannot invest in certain companies), heterogenous beliefs (a fancy way of saying that investors “agree to disagree”), and herding behavior (e.g. meme stocks).
So in the most liquid, most efficient, most studied market in the world, unmeasured factors dominate measured ones by 4:1. How much of AI demand could we realistically hope to explain?
Not much. A non-exhaustive list of factors that could drive one’s choice of LLM:
Reliability and uptime guarantees (you know who you are)
Safety policy and content moderation posture (you also know who you are)
Tooling and ecosystem integration
Support quality and SLAs
Privacy and data retention policies
Brand and reputational risk
These are dimensions that benchmarks like MMLU and SWE-Bench don’t capture. The ~10x price premium for equally intelligent closed source models hints that these unobserved factors really do matter. It's the LLM equivalent of Koijen and Yogo's finding: latent demand is the rule rather than the exception.
The AI economists acknowledge this:
There are two potential explanations for this gap. First, the Intelligence Index may not fully capture important differences in model capabilities. Second, users may systematically discount the value of open-source models—either because of actual or perceived differences such as weaker brand reputation, privacy concerns, or less extensive customer support – The Emerging Market for Intelligence: Pricing, Supply, and Demand for LLMs
Both explanations point to the same conclusion: latent demand is most of the demand.
In fact, the price regressions we looked at earlier show exactly that: intelligence only explains 10% of price variation across LLM providers. Adding in other characteristics like whether the model is open source, reasoning capabilities, context length, and age only gets you to ~45%.
Only by controlling for the model creator (e.g. Anthropic, OpenAI, DeepSeek, etc) are we able to explain more than half of LLM pricing variation. Further, controlling for whether the model is open source muddies the water a bit, since most model labs are either fully open or fully closed source, meaning some of what open source is “explaining” is actually a brand effect.
In total, this data suggests that the identity of the model creator is the biggest single explanatory factor in LLM pricing.
If it fits, it sticks
One way to explore this brand effect is to observe the degree to which users stubbornly “stick” to a particular model, i.e. the degree to which they maintain strong preferences irrespective of price or evolving alternative options.
Here again we can analogize to the stock market. In the decomposition of stock returns from before, the researchers broke latent demand into two parts: the “extensive margin” (certain investors only buying certain stocks) and the “intensive margin” (how much of each stock investors hold, assuming they hold the stock at all).
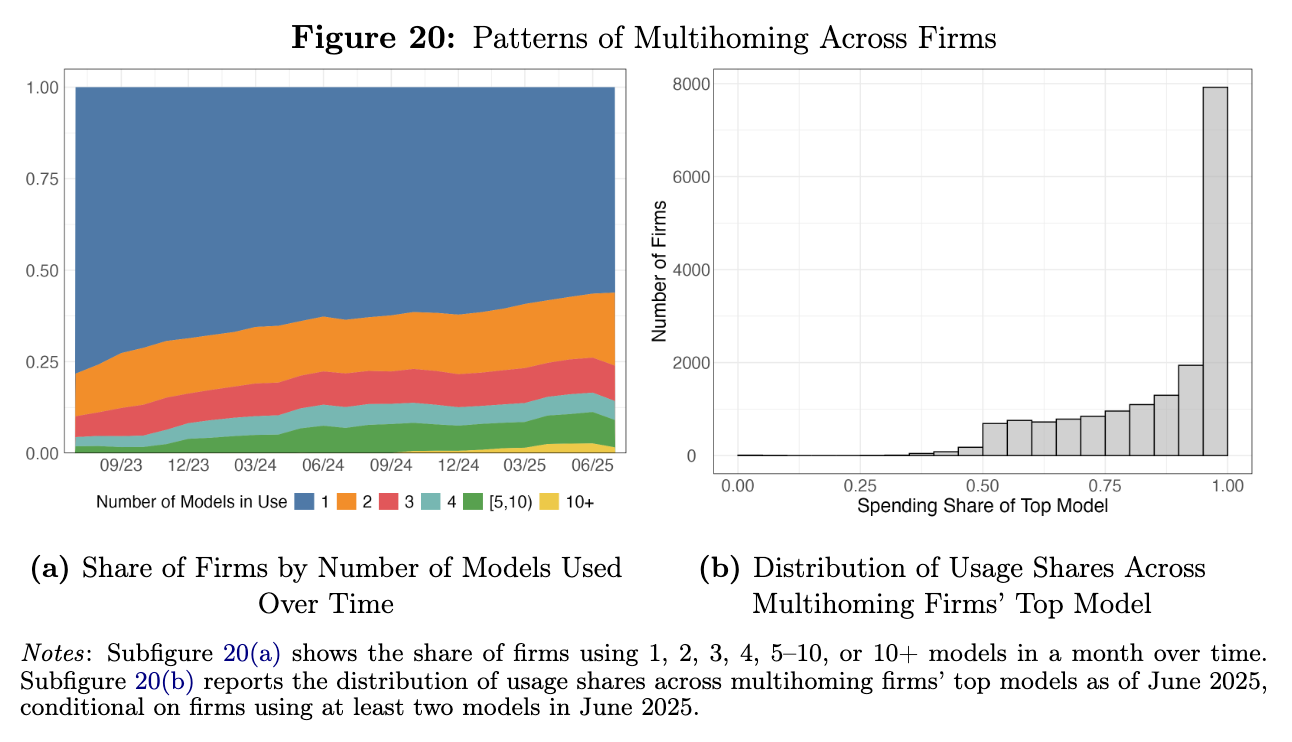
Applying this framework to the OpenRouter data, we see substantial evidence for both the extensive and intensive margins playing a role. For example, users concentrating all of their usage on a single model aligns with the extensive margin, while users using many models but varying in how they distribute their use cases between them points to the intensive margin.
The data? Just over 50% of OpenRouter users use only one model. Among those that use multiple models, a very large share of users allocate almost all their usage to only one of those models:
That is to say, to the extent users leverage multiple models, it’s mostly for experimental purposes rather than production use. When it’s time to get serious, most users make a singular choice and stick with it. The extensive margin dominates.
OpenRouter themselves recently published their own analysis which came to a similar conclusion, which they call the “Glass Slipper effect” in a nod to Cinderella:
The hypothesis posits that in a rapidly evolving AI ecosystem, there exists a latent distribution of high-value workloads that remain unsolved across successive model generations. Each new frontier model is effectively “tried on” against these open problems. When a newly released model happens to match a previously unmet technical and economic constraint, it achieves the precise fit — the metaphorical “glass slipper.”
For the developers or organizations whose workloads finally “fit,” this alignment creates strong lock-in effects. Their systems, data pipelines, and user experiences become anchored to the model that solved their problem first – State of AI: An Empirical 100 Trillion Token Study with OpenRouter
In the LLM market, it’s a competition to be someone’s #1 pick, and there’s no prize for 2nd place.
Genius is not homogenous
The LLM market presents a puzzle: massive price dispersion at equivalent measured intelligence, persistent market share gaps between closed and open source models despite premium pricing, concentrated usage patterns at the user level despite a panoply of options.
Old school asset pricing models failed because they assumed homogenous investor preferences. In the famous CAPM model, everyone holds (or at least should hold) the market portfolio. In reality, investors have wildly divergent preferences that show up as latent demand.
Similarly, the obsession with model benchmarks assumes homogenous user preference for intelligence over all else. But in fact users have varying preferences that benchmarks don’t and can’t reflect.
So what are the implications? Here’s a crack at a few:
Models aren't commodities (yet): It seems many users are willing to pay a premium for quality, capabilities, or stability. Differentiation is possible, and the inordinate influence of latent demand reflects that
Moats aren't about weights: Defensibility may be less about locking down model weights and more about trust, safety posture, and other intangibles
Benchmarks measure what's measurable: We’re measuring what’s easy to measure, not always what matters. Most of what drives relative LLM adoption lives in dimensions that are hard to quantify. Benchmark-maxxing isn’t everything.
The benchmark obsession is understandable. Numbers are legible. Rankings are simple.