- Title: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
- Authors: Anonymous (Paper currently in blind review for ICLR 2021)
- One sentence summary: Large Transformer trained on large datasets outperform CNN-based architectures and achieve state of the art results on image recognition tasks
- Source: https://openreview.net/forum?id=YicbFdNTTy
- Compression: 8 pages (original ex. references and appendix) -> 3.75 pages (this article)
An Image is Worth 16x16 Words: Transformers for Image Recognition (Paper Explained)

Join the Syndicate
Long-form essays on the economics of tech, with the data to back it up. All signal, no noise.
Read by 5,000+ founders, engineers, and investors.
Summary
"An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale" introduces the Visual Transformer, an architecture which leverages mostly standard Transformer components from the original NLP-focused "Attention is All You Need" paper but instead applies them to computer vision, specifically image recognition. Images are transformed into sequences of image patches representing "tokens," similar to word tokens in NLP. The model is trained in supervised fashion on image classification using these patch sequences as input.
The image-based Transformer does not outperform CNNs when trained on mid-sized datasets such as ImageNet, underperforming similar-sized ResNet models. This is likely due to an inability overcome the inherent advantage of CNNs (inductive biases like translational equivariance and locality). However, when the Transformer model is pre-trained on large image datasets (specifically, JFT) and transferred to other tasks, the model achieves SOTA results.
The strong results suggest the long hoped-for convergence of architectures across NLP and computer vision may finally be here in the form of Transformers. Per Andrej Karpathy, Director of AI at Tesla:
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale https://t.co/r5a0RuWyZE v cool. Further steps towards deprecating ConvNets with Transformers. Loving the increasing convergence of Vision/NLP and the much more efficient/flexible class of architectures. pic.twitter.com/muj3cR6uGA
— Andrej Karpathy (@karpathy) October 3, 2020
Key results and takeaways
- Large Vision Transformer model mapping patches of image to classification labels outperforms CNN-based architectures and achieves state of the art results when trained on large (100M+ images) datasets
- Transformer model underperforms CNNs when only trained on mid-sized datasets
- Early layers of the Vision Transformer are able to attend to large chunks of the image, unlike traditional convolutional layers with are constrained to a local window
- Self-supervised pre-training with "masked patch prediction" achieves decent results but underperforms supervised pre-training
Methodology
Architecture
The model effectively analogizes between words as tokens of larger sentences and groups of pixels as "tokens" of larger images. Like a sequence of word tokens makes a sentence, a sequence of pixel patches makes an image. Thus, the input image is broken up into multiple patches of
Image patches
The representation of the first token in the output of the final Transformer encoder layer serves as the image representation. The classification head is attached to only this token. Position embeddings are added to the patch embeddings, and these vectors serve as input to the encoder.
The Transformer architecture is constructed as follows:
where
Layer representations
The authors construct multiple versions of the model at various scales to compare results across model size, similar to BERT. Base = "B", Large = "L", Huge = "H".
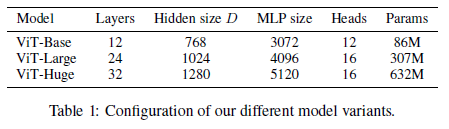
The authors also experiment with a hybrid architecture, where instead of using patches as the input sequence, the intermediate representation of a ResNet model is used, replacing the patch embedding. The rest of the architecture remains unchanged.
Training
Models are (pre-)trained on multiple image datasets, including ImageNet (1K classes / 1.3M images), ImageNet-21K (21K classes / 14M images), and JFT (18K classes / 303M images). As the largest dataset, JFT-300M is the main focus of the paper, which we will see enables big performance improvements when used in the largest versions of the architecture. Here, the model is pre-trained for 1M steps. The remaining training hyperparameters can found be found in the paper.
The Vision Transformer is fine-tuned at higher resolution than pre-training, which helps performance. However, higher resolution images have more pixels, so the patch sequences are longer. Rather than create extra positional embeddings for these additional tokens, the existing embeddings are interpolated such that multiple higher resolution patches correspond to each lower resolution positional embedding. This is necessary as the additional positional embeddings would not have been seen during pre-training and hence would be meaningless if applied directly. This is the only point in which inductive bias about the structure of images enters into the Vision Transformer.
Experiments and results
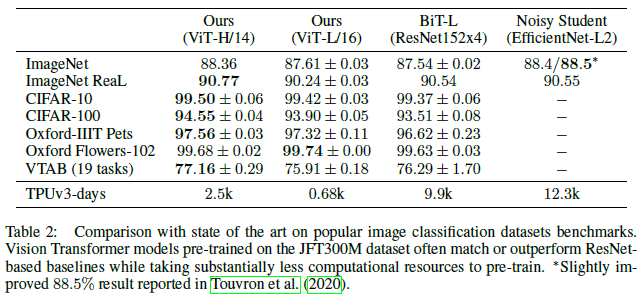
The authors choose a number of benchmark tasks for performance evaluation: ImageNet, ImageNet ReaL, CIFAR-10/100, Oxford-IIIT Pets, Oxford Flowers-102, and the 19-task VTAB classification suite.
Performance
ViT-L/16 matches or outperforms BiT-L (large ResNet that supports supervised transfer learning) on all datasets with 4-10x fewer computational resources used during pre-training (as measured by TPUv3-days):
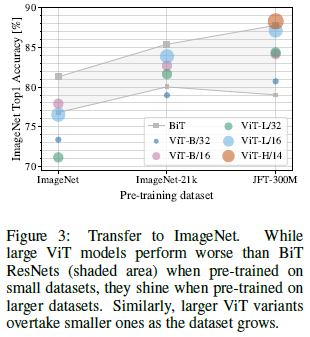
This performance advantage disappears if ViT is trained on a smallest dataset, such as ImageNet. Only with the largest dataset, JFT-300M, do larger models outperform all others:
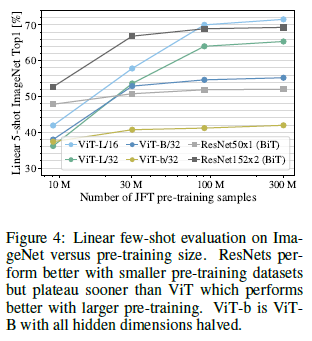
ViT-B/16 and ViT-B/32 do not gain as much from being trained on larger datasets. This alludes to the intuition that the convolutional inductive bias is most useful for smaller datasets. On larger datasets however, learning the patterns directly is better:
Performance vs. compute cost
The Vision Transformer outperforms ResNets in terms of the performance / compute ratio. ViT uses half as much compute to attain the same performance level (x-axis is pre-training exaFLOPs on log scale):
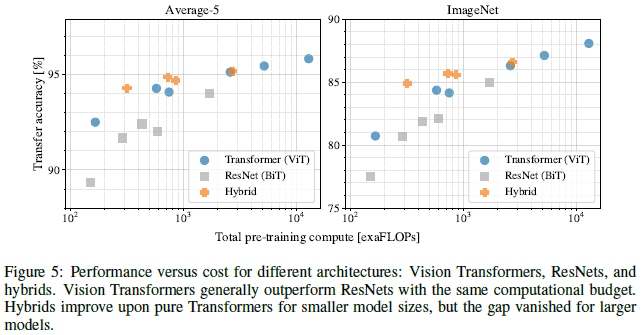
Interestingly, hybrids slightly outperform the Vision Transformer with small computational budgets but not for larger ones. The authors note their surprise at this result, as it might be expected that convolutional feature maps coming from ResNet would be helpful at any scale
Global self-attention
Self-attention allows the Vision Transformer to integrate information across the entire image, even in the lower Transformer layers. This is unlike CNNs, where only the later layers are able to aggregate information from different parts of the image. Experiments show that the "attention distance" of the attended area is large in the later layers, as expected, but also large in some portion of the earlier layers, demonstrating the ability to learn long-range dependencies. For example, some of the earlier layers heads attend to patches 100 pixels away from on another (right chart below):

The model clearly attends to image regions that are most relevant for classification:

Self-supervised pre-training
The authors experiment with self-supervised pre-training using "masked patch prediction," mimicking masked language modeling in the NLP context. With this training regimen, ViT-B/16 achieves 79.9% accuracy on ImageNet, a 2% improvement relative to training from scratch, but 4% lower than supervised pre-training used in the rest of the paper.
Reflection
OK, so this is exciting stuff. Personally, I've never liked convolutions, for similar reasons that I've never liked recurrent neural networks. There just something complicated about them. Something inelegant. I've always loved more linear architectures, largely composed of feedforward layers with various augmentations like normalization or residual skip connections, i.e. Transformers and attention-based networks in general (and yes I know it's possible to rewrite convolutions as affine transforms). So I think it's very cool to finally see this applied to computer vision with strong results.
I don't know if there were enough ablations to totally prove this, but it seems like insufficient data was the core blocker preventing linear transformations from achieving similar results to CNNs. The inductive biases of CNNs have always been their key advantage, but that advantage seems to wither under the weight of massive global self-attention learned on massive image datasets, at least for image recognition / classification.
The authors also note that, given performance does not yet appear to saturate with increasing model size, the Vision Transformer could potentially be scaled up even further. Nice.
A couple wrinkles to point out.
The paper is currently under double-blind review for conference submission at ICLR 2021, so the authors remain anonymous for now. That said, I'd be shocked if it wasn't Google behind this paper. There are a few tells, like the fact that they use TPUs (Google-specific hardware) for training and the JFT-300M dataset (a Google maintained dataset). As of right now, it doesn't appear the JFT-300M is publicly available -- only Google researchers have access. Therefore, even if the code was made publicly available (which I'm guessing it won't), the results are not replicable. As readers, we have no idea what architectural tricks may have been used that are not made clear by the text of the paper itself, so reproducibility is not guaranteed.
Second, as some folks on Twitter have noted, using these 16x16 patches as input to the model is likely suboptimal. It's at best a first step and the strong performance of the hybrid version of the model (which uses intermediate ResNet representations as input) suggests as much.
As noted before, convolutions seems to help most in low-data / compute regimes, helping the model perform better with less training time for all but the largest model and dataset. Future research may reveal better ways to represent the input image while still avoiding the use of convolutions. If I had to guess, as in NLP, self-supervised pre-training will be key.
Join the Syndicate
Long-form essays on the economics of tech, with the data to back it up. All signal, no noise.
Read by 5,000+ founders, engineers, and investors.