visual essay prototypeAPR 27, 2026Confidence · medium
Tokens Aren't Fungible
Open-source LLMs can be dramatically cheaper at similar benchmarked intelligence, yet closed-source models still capture most token volume. The market is saying that tokens carry hidden attributes benchmarks do not measure.
Working thesis
Tokens are not fungible because users buy fit, trust, workflow integration, and brand — not just benchmarked intelligence per dollar.
Cheaper conditional on measured intelligence in the cited market study.
Open-source token share
<30%
Persistent minority share despite the price advantage.
Price explained by intelligence
~10%
Benchmark intelligence alone explains little pricing variation.
Interactive instrument
How much of LLM demand lives outside the benchmark?
A deliberately simple toy model for the essay’s core puzzle. If cheaper open models still hold minority token share, and measured variables leave most behavior unexplained, demand is probably hiding in unmeasured fit, trust, workflow, and brand.
With open models at 30% token share despite a 90% price discount, the toy model flags 56% latent-demand pressure. Translation: benchmarked intelligence and price are not the whole product.
Unexplained demand
Price defiance
Lock-in pressure
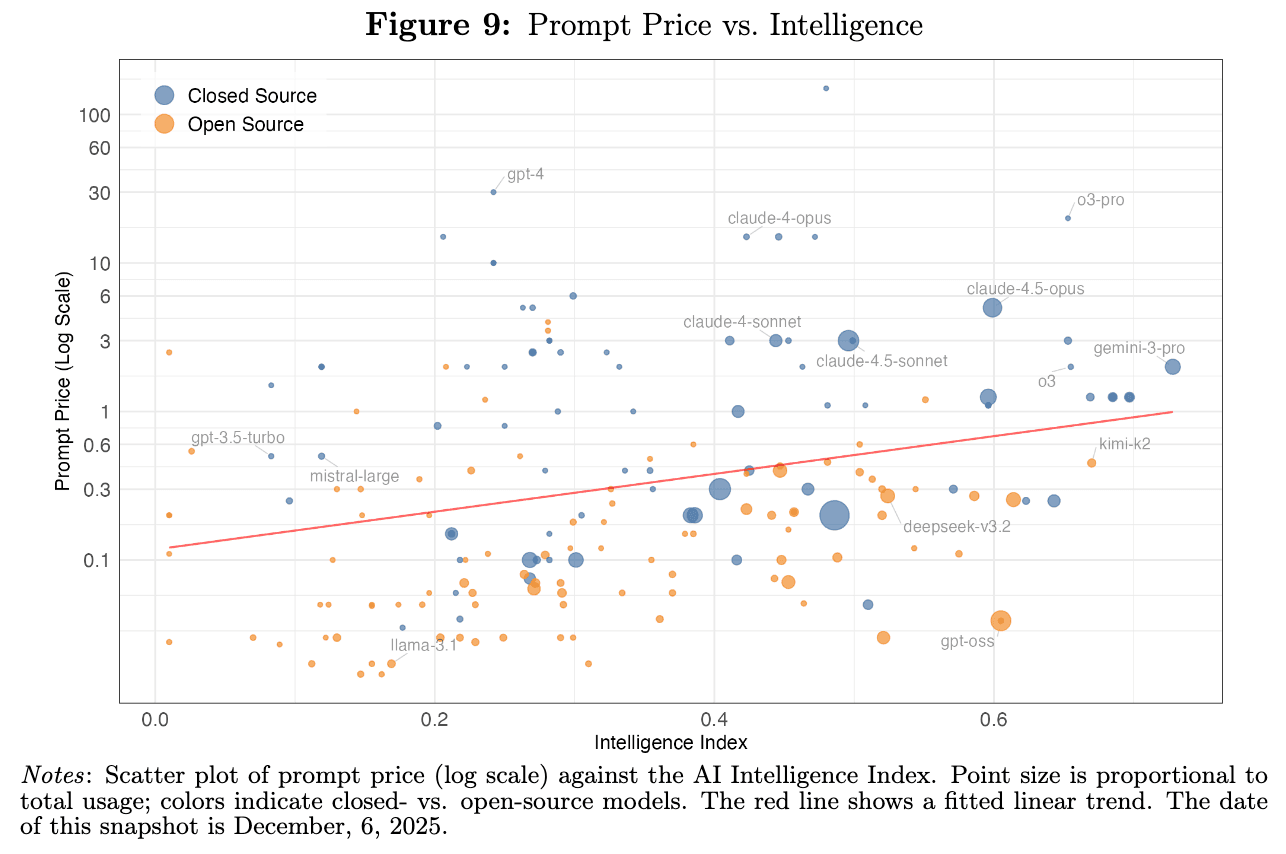
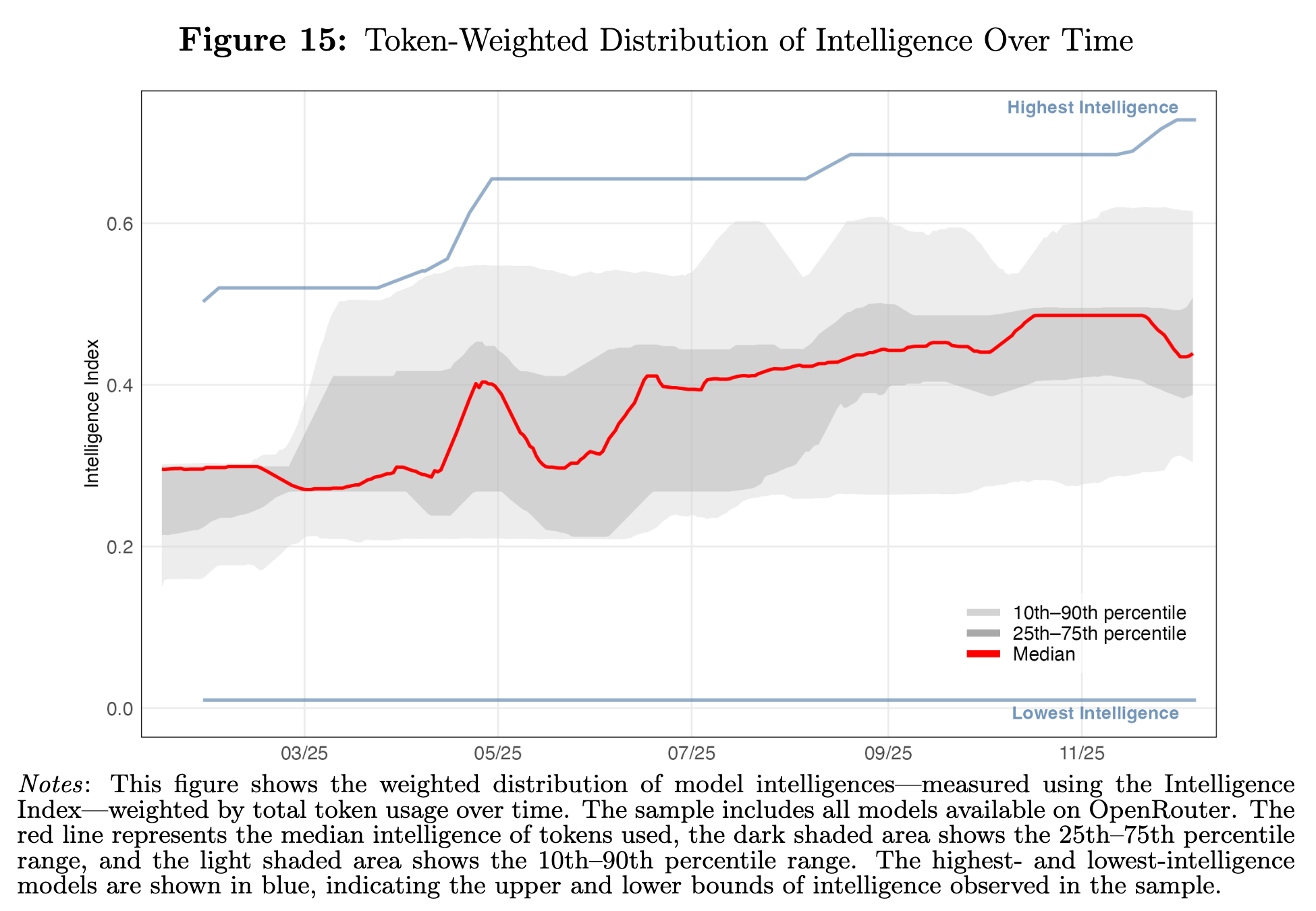
Exhibit 01 — Open-source models can be much cheaper at similar measured intelligence. The puzzle is why that price advantage does not dominate token demand.
Open-source LLMs are roughly 90% cheaper than closed-source models at the same benchmarked intelligence level.
Yet they capture less than 30% of token share.
If intelligence were the only thing users cared about, the cheaper model should win. If price were the main thing users cared about, the cheaper model should win even faster.
It has not.
That is the puzzle. The LLM market looks like a commodity market from far away — tokens in, tokens out, benchmark scores, price sheets — but users are behaving as if each token carries hidden attributes. Reliability. Trust. Workflow fit. Safety posture. Privacy. Brand. Ecosystem integration. Latency. Support. The stuff that is hard to summarize in a leaderboard.
Working definition. Tokens are fungible only if a user is close to indifferent between two providers at the same measured intelligence, latency, reliability, policy, trust, integration, and price. The market evidence says users are not indifferent.
Join the Syndicate
Long-form essays on the economics of tech, with the data to back it up. All signal, no noise.
Read by 5,000+ founders, engineers, and investors.
The puzzle: the cheap intelligence does not clear the market
The standard commodity intuition is simple: at the same quality, the cheaper supplier should win.
That intuition is powerful because it is usually right. If two cloud providers offer identical compute, the cheaper one should take share. If two exchanges offer identical liquidity and execution, price matters. If two models are equally intelligent and one costs a fraction of the other, why would users keep paying up?
The opening chart makes the puzzle visible: open models sit below closed models on price at similar measured intelligence.
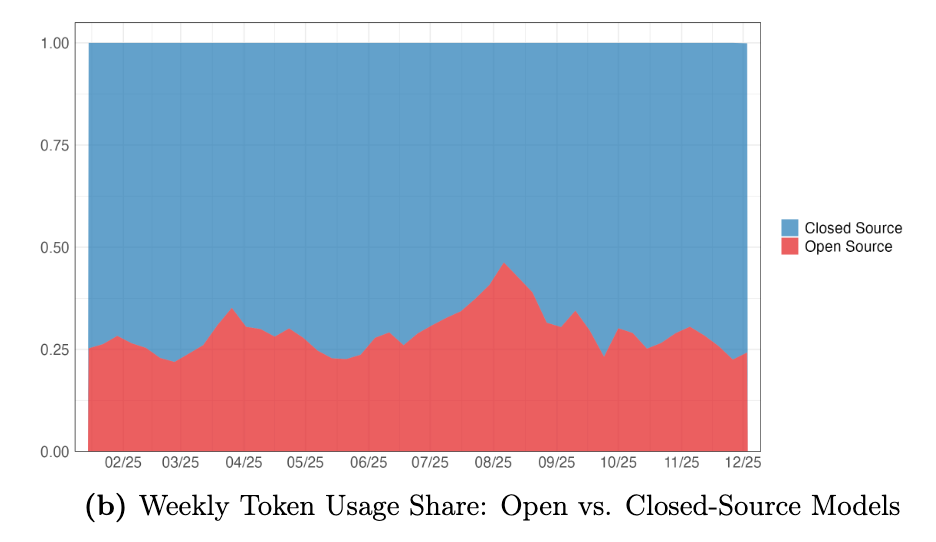
But the quantity side refuses to follow the price chart. Open-source models remain below 30% of token share. OpenRouter even describes this as an equilibrium.
Exhibit 02 — Open-source share remains stubbornly below 30%. The quantity market refuses to behave like a simple benchmark-adjusted commodity market.
So the question is not whether open models are good. Many are. The question is why the market keeps paying for something beyond benchmarked intelligence.
Primer: six ideas the argument depends on
Concept 01
Measured intelligence
Benchmark scores compress model capability into a legible number. Useful, but incomplete: many production attributes are not measured.
Concept 02
Token share
Token volume is revealed preference. It shows what users actually route into production, not what they say they admire.
Concept 03
Quality-adjusted price
Price divided by benchmarked intelligence sounds like a commodity metric. The problem is that intelligence is not the whole quality vector.
Concept 04
Latent demand
Borrowing from asset pricing, latent demand is demand for attributes the econometrician cannot observe or measure cleanly.
Concept 05
Extensive margin
Many users do not continuously optimize across all models. They choose one model-provider combination and stick with it.
Concept 06
Glass slipper fit
A model can become valuable because it solves one user’s awkward, high-value workload first. Once embedded, the fit becomes sticky.
The central decomposition is:
Benchmarks, context length, reasoning flags, open-source status, and price live on the observed side. Workflow fit, trust, policy acceptance, support quality, internal switching cost, and brand risk often live on the latent side.
The naive model: intelligence is a commodity
The naive model says users buy intelligence. If two models have the same measured intelligence, they are close substitutes. Price should do most of the remaining work.
That model predicts three things:
open-source share should rise when open models get much cheaper at the same intelligence;
price should explain a large share of token demand;
benchmark-adjusted prices should converge over time.
The evidence points in the opposite direction.
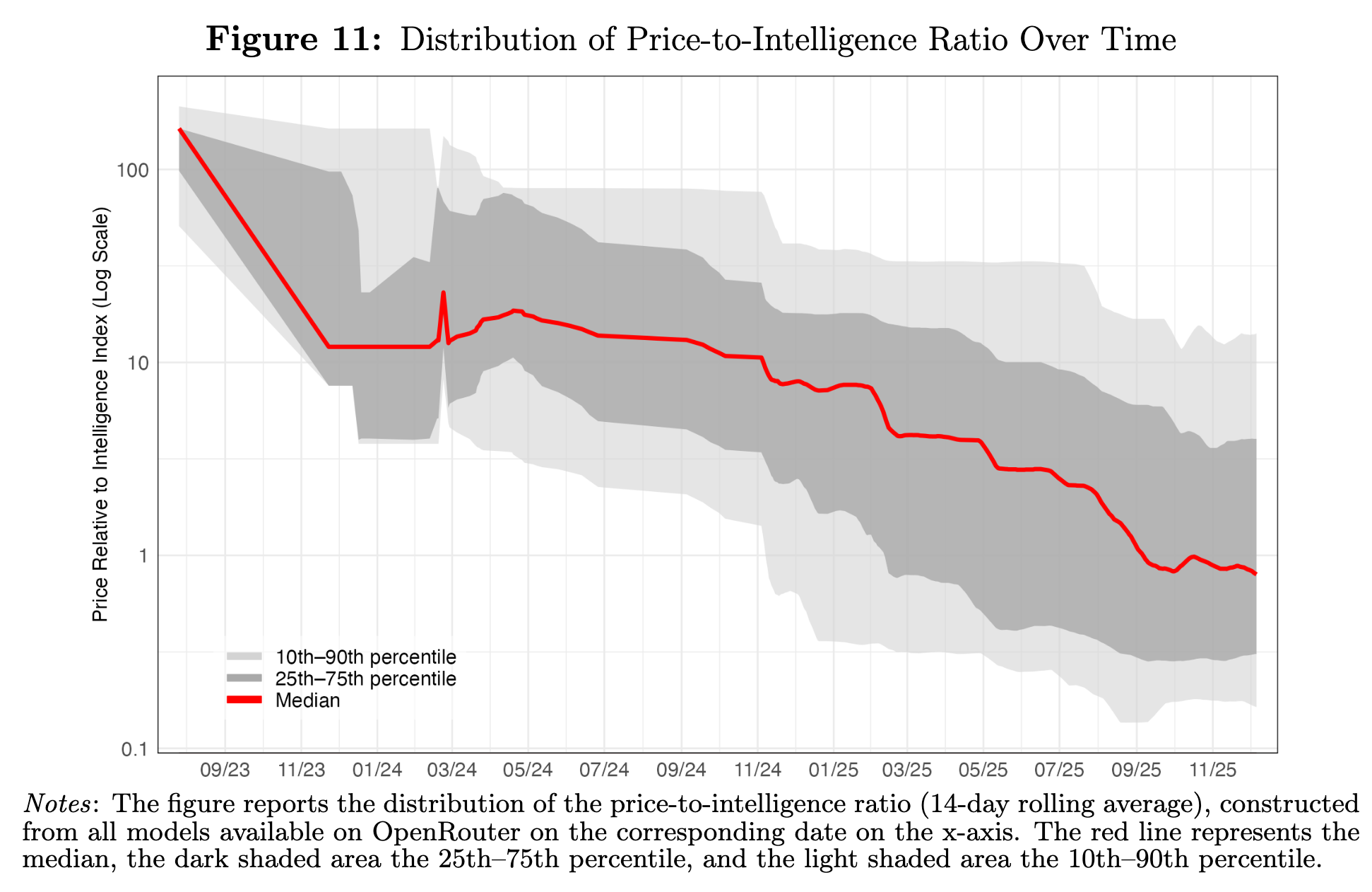
Exhibit 03 — Quality-adjusted price dispersion does not collapse. If intelligence were enough, this spread should be harder to sustain.
Naive prediction
What the market shows
Interpretation
Underwriting implication
Cheaper equal-intelligence models should take share
Open-source share remains below 30%
Measured intelligence is not sufficient
Do not underwrite model demand as pure benchmark arbitrage
Price should explain most volume
Prices matter, but explain limited within-model demand variation
Choice happens before marginal price optimization
Study model selection and lock-in, not only token price
Quality-adjusted prices should compress
Price dispersion remains wide and can increase
Users pay premiums for hidden attributes
Look for trust, integration, reliability, and brand effects
The LLM market is not telling us intelligence does not matter. It is telling us intelligence alone is not enough to describe the product.
The failure mode: benchmarks measure what is measurable
Benchmark scores are useful because they are legible. That is also why they are dangerous.
A benchmark can tell us whether a model answers a certain class of questions well. It cannot fully tell us whether a customer trusts the provider with sensitive data, whether the model behaves predictably inside a brittle workflow, whether policy refusals are acceptable, whether uptime is good enough, whether procurement likes the vendor, or whether the support team will pick up the phone.
Those attributes are not soft. They are product quality.
Key inversion. The hidden attributes are not “extra” features around the model. For many production users, they are the thing being purchased.
This is why equally intelligent tokens can have different economic value. A token from a model that fits the workflow, passes internal risk review, and has predictable behavior is not equivalent to a cheaper token that creates operational uncertainty.
The better model: latent demand dominates the residual
Asset pricing has a useful analogy. In a demand-system view of markets, investors demand stocks for both observable characteristics and unobservable preferences. Koijen and Yogo call the unobserved component latent demand.
That language maps surprisingly well to LLMs.
Observable characteristics include:
benchmark intelligence;
price per input/output token;
open vs closed source;
context window;
reasoning capability;
model age;
provider identity.
Latent demand includes:
reliability and uptime;
safety and policy posture;
privacy and data retention;
toolchain integration;
support and SLA quality;
brand risk;
internal trust;
switching costs;
weird workload-specific fit.
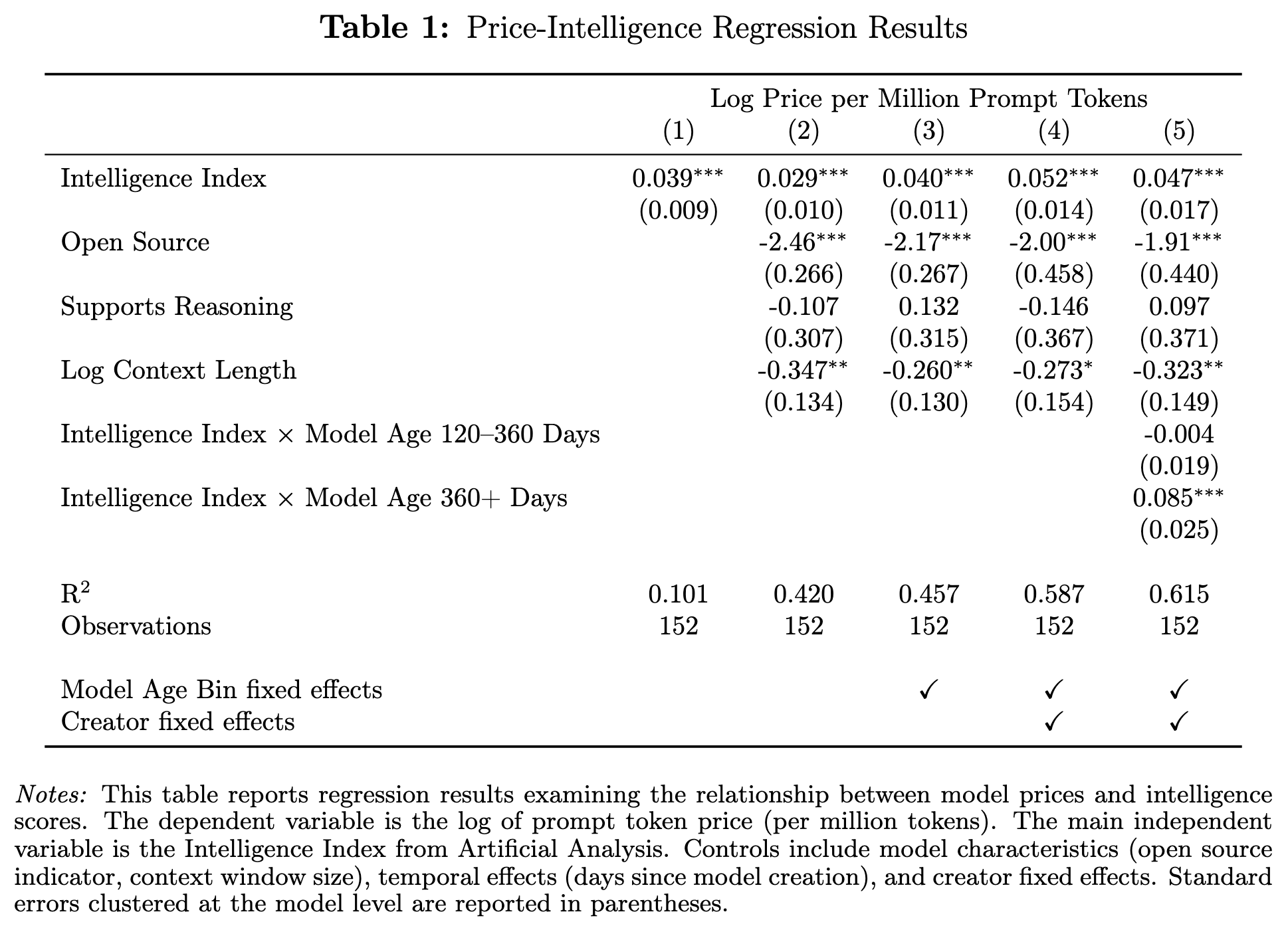
The cited market evidence says intelligence alone explains only about 10% of pricing variation. Adding observable controls helps, but a large residual remains. The residual is not noise to ignore. It is the market telling us where the product actually lives.
Exhibit 04 — Intelligence alone explains little price variation. Provider identity and other controls move the fit, which is exactly where latent demand starts to show up.
Evidence check: the market keeps revealing hidden preference
The original essay walks through price dispersion, quantity concentration, regression results, and model stickiness. The exact numbers matter less than the pattern: measured variables explain some behavior, but not enough.
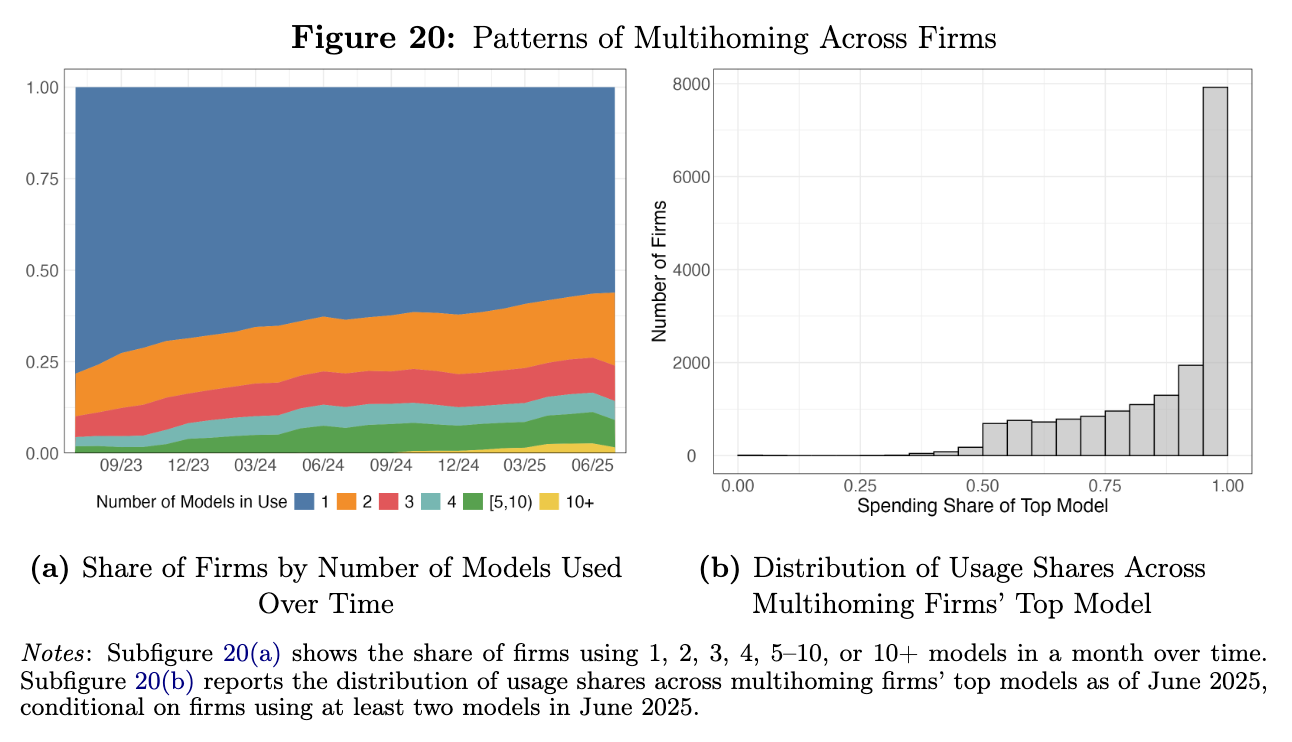
Exhibit 05 — Actual token use is not concentrated entirely at the frontier. Many users choose models below the maximum measured intelligence available.
Evidence
Observed fact
What it rules out
What it suggests
Price vs intelligence
Open models are far cheaper at similar benchmarked intelligence
Pure intelligence-per-dollar clearing
Users value non-benchmark attributes
Open-source token share
Share remains below 30%
Fast migration to cheaper substitutes
Trust, fit, and integration resist price pressure
Pricing regressions
Intelligence alone explains little price variation
Benchmarks as sufficient statistic
Provider identity and other attributes matter
User concentration
Many users concentrate on one model
Constant fine-grained optimization
Extensive margin and lock-in dominate
This is the part investors should sit with. A lower price can be real and still fail to move demand. A higher benchmark score can be real and still fail to win a workload. A model can be technically impressive and commercially second-choice.
The glass slipper: when fit beats frontier rank
OpenRouter’s “glass slipper” framing is a good way to understand the extensive margin.
A user does not necessarily search continuously for the globally optimal model. More often, they have a specific workload with awkward constraints. They try models until one fits. Once it fits, the model becomes embedded in prompts, evals, data pipelines, monitoring, cost expectations, latency budgets, product behavior, and internal trust.
At that point, switching is no longer a spreadsheet exercise.
Exhibit 06 — The extensive margin dominates. Many users concentrate on one model, suggesting production fit and lock-in matter more than continuous price shopping.
Before fit
Experimentation
Many models are tried. Price and benchmark rank matter because the system has not committed yet.
Moment of fit
Constraint match
One model satisfies the actual workload: policy, latency, accuracy, reliability, integration, and trust.
After fit
Embedded demand
The model becomes part of production. Switching requires re-testing, re-risking, and re-learning the system.
The prize is not to be everyone’s second-best model. The prize is to become someone’s production default.
What this means for AI underwriting
If tokens are not fungible, then AI market underwriting should not stop at benchmark charts.
The diligence target shifts from “which model is smartest?” to “which provider owns hidden demand attributes that are durable?”
What to verify
Reliability: Does the model behave predictably enough for production?
Workflow fit: Is it embedded in a high-value, repeated job?
Switching cost: What would break if the customer moved models?
Trust: Does the buyer believe the provider is safe enough for sensitive use?
Policy posture: Are refusals, moderation, and safety behavior acceptable for the workload?
Support: Does the vendor help when the system fails?
Brand risk: Would the buyer be comfortable defending the provider choice internally?
These are not easy to measure. That is the point. The unmeasured attributes may be where the margin lives.
A practical decision rule
Underwriting shortcut. Do not ask only whether the model is smart. Ask whether users would feel real pain if they had to replace it tomorrow.
The claim to watch
The market keeps saying the same thing in different ways: the benchmark is not the product, and the token is not the unit of differentiation.
The product is the full bundle that gets a user from uncertain task to trusted output. Some of that bundle is measured. Most of it is not.
That is why tokens are not fungible.
Join the Syndicate
Long-form essays on the economics of tech, with the data to back it up. All signal, no noise.
Read by 5,000+ founders, engineers, and investors.