(I'm trying something new: summarizing and explaining technical research papers I come across. I spend a ton of free time reading these so I figure why not put some of that time spent to good use? Hoping this benefits others who are knee-deep in machine learning and econometric research.)
One sentence summary: Transformer model pre-trained on document retrieval and reconstruction performs surprisingly well on wide range of fine-tuned and zero-shot / unsupervised downstream tasks
Long-form essays on the economics of tech, with the data to back it up. All signal, no noise.
Read by 5,000+ founders, engineers, and investors.
Summary
"Pre-training via Paraphrasing" introduces MARGE, a Multilingual Autoencoder that Retrieves and Generates. In this architecture, a retrieval model is trained to score the relevancy of batches of "evidence" documents based on their similarity to a "target" document . Simultaneously, a reconstruction model is trained to reconstruct the original target document conditioning on the evidence documents and their relevance scores from the retrieval model. This back-and-forth emulates the behavior of an autoencoder (or even a denoising autoencoder) whereby the mapping of target document to evidence documents serves as an information bottleneck forcing the model to learn document representations that will best enable the reconstruction of the input document.
Once pre-trained on this "paraphrasing" task, MARGE can then be leveraged for downstream tasks like sentence retrieval, machine translation, summarization, paraphrasing, and question answering. Even with no fine-tuning (i.e. "zero-shot"), the model demonstrates impressive performance on these tasks. Performance improves meaningfully with task-specific fine-tuning.
Key results and takeaways
Transformer-based model pre-trained on retrieval / reconstruction performs admirably across multiple downstream generative and discriminative tasks, including state of the art (SOTA) results on some tasks
Achieves BLEU scores of up to 35.8 on zero-shot unsupervised document translation with no task-specific fine-tuning
Outperforms other unsupervised models on unsupervised cross-lingual sentence retrieval by large margin
Impressively, model is trainable from random initialization despite "chicken-and-egg" problem of retrieval and reconstruction models being co-dependent
Methodology
Retrieval and reconstruction together act as an autoencoder. The retrieved documents act as a noisy representation of the input, and this process serves as an information bottleneck for the algorithm (an encoder). The meaning of the original input is therefore encoded in these documents via the choice of which documents to retrieve along with the relevance score assigned to each. This mapping of input to retrieved documents is the "encoder" of the autoencoder. The reconstruction of the input via the retrieved documents is effectively the decoder.
Both the encoder and decoder here have a Transformer-like architecture with multi-headed attention calculated across multiple layers.
Retrieval model
The input to the MARGE model is a batch of "evidence" (the documents to be retrieved) and a "target" (the document to be reconstructed). Batches are created by:
sharding the document dataset into groups of potentially documents using heuristics like publication date
taking the evidence documents within the shard most similar to the target document (according to below)
including a subset of these documents in the batch, weighting documents in other languages more than same-language documents
Batches are dropped and regenerated offline every 10K training steps by re-computing the pairwise relevance scores across documents.
The retrieval model compares candidate documents by computing a pairwise relevance score between a target document and evidence document from the corpus. This takes the form of the cosine similarity of the documents, encoded by a function , which takes the form of the first token of a 4-layer Transformer network:
These relevance scores are used both to select documents to be included in each batch as well as push the model to pay more attention to more similar documents when reconstructing the input, as I'll cover later on.
Using the same function for both targets and evidence ensures documents with similar words are more likely to be mapped to similar representations, even if the encoding function is largely random (which it will be at initialization).
Reconstruction model
The reconstruction model computes the likelihood of the target document tokens, conditioned on the evidence documents within the batch and associated relevance scores. The vector representations for all evidence documents within each batch are concatenated together into a single vector before being used for reconstruction:
During decoding, attention weights are calculated for each token of the target across the set of concatenated evidence documents, meaning that the weights correspond to the attention the decoder should pay to each token of each evidence document at each time-step, capturing token-wise similarity as in standard dot-product attention. Here however, the relevance scores for each document are added to the attention scores for the tokens from that document, multiplied by a trainable scalar parameter . These biased scores are then softmaxed, yielding the attention weights for each time-step, layer , and attention head :
Backpropagating the reconstruction loss improves both the reconstruction model and the relevance model via this attention mechanism.
Architecture and training
The model encoder (distinct from the encoder used to encode individual documents) is a 12-layer Transformer network with dimension 1024 and feedforward layers of size 4096. The decoder is similar in structure but the feedforward layers there are size 16536 and 4 additional Transformer layers are added to the base with only self-attention (i.e. attention only to other words within the same document) and feedforward layers of size 4096. These supplemental layers allow the words in the target to contextualize locally before doing so across documents. The first four layers of the encoder are used in the relevance model (this is the referred to above).
The model is initially pre-trained on the CC-NEWS corpus for 1M total steps. At this point, the checkpointed model is referred to as MARGE-NEWS. Then, the authors further pre-train for an additional 100K steps on Wikipedia, referring to the resulting model as MARGE.
For fine-tuning, a different procedure is used for generation and classification problems. For generation (translation, summarization), the task input is fed into the encoder and the final output is generated by the decoder. For classification, the task input is fed into both the encoder and decoder
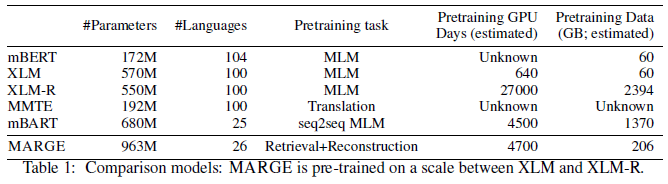
The MARGE model ends up with 963M parameters, more than most of its comparison set of "the strongest available multi-lingual pre-trained models" (mBERT, XLM, XLM-R, MMTE, mBART), but is trained on fewer languages and a medium-sized dataset and a medium amount of GPU pre-training days:
Experiments and results
The papers show the wide applicability of MARGE and its paraphrasing pre-training technique by evaluating its performance across wide array of NLP tasks. MARGE performs well across many tasks, wider than any previous pre-trained model. This includes zero-shot document translation, and performance improves further with fine-tuning. The strong results of MARGE establish retrieval / reconstruction as a viable alternative to MLM for pre-training. The success of the method is partly driven by the higher relatedness of the pre-training task to downstream tasks.
Document-Level Machine Translation
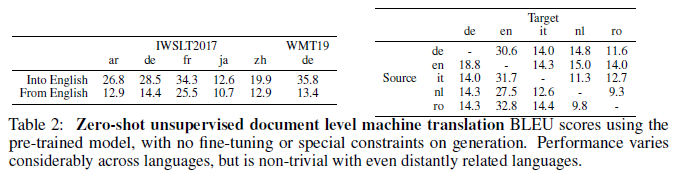
The authors demonstrate the models strong translation performance across a number of language pairs and within both zero-shot and fine-tuned settings, achieving 35.8 BLEU in the case of unsupervised translation from German into English on the WMT19 dataset, the highest score ever achieved by a system trained with no bitext (as in iterative back-translation). Performance does vary significantly by language:
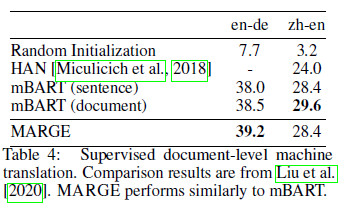
Supervised translation with labeled bitext improves performance further, achieving competitive results against mBART:
Cross-lingual Sentence Retrieval
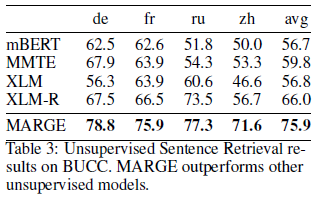
It would make sense that a model trained retrieve similar documents, sometimes in a different language, would perform well on a sentence retrieval task. Confirming this intuition, MARGE outperforms other unsupervised models by almost 10 points on the BUCC2018 benchmark, though the embeddings are tuned somewhat on BUCC development data:
Summarization
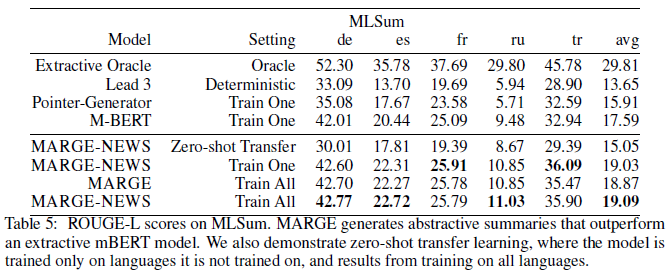
The authors evaluate the model's performance on monolingual sequence-to-sequence generation via text summarization tasks sourced from the MLSum dataset. Performance is compared across multiple languages, and the extractive oracle performance level is shown for comparison-sake. What's impressive here is that MARGE's summaries are inherent abstractive - the model is generating summaries in its own words, not simply extracting words from the input text - and yet it manage to outperform an extractive mBERT model on a fundamentally extractive performance metric (ROUGE-L). This is not trivial to do:
Question answering and paraphrasing
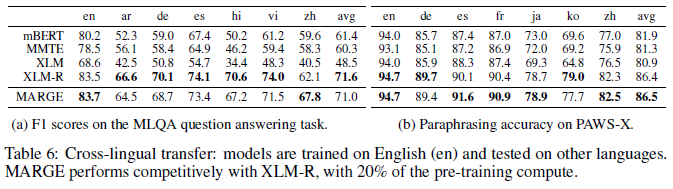
The MLQA dataset is used to test MARGE's performance on question answering. MARGE what over or underperforms XLM-R depending on the language, on average underperforming by a small margin (as measured by F1 score). Paraphrasing is tested on the PAWS-X paraphrase detection dataset, where the model is trained on English and zero-shot transfer is tested on other languages. MARGE demonstrates SOTA performance relative to XLM-R:
Conclusion
I think this is an interesting paper mainly due to its demonstration of a new pre-training methodology that appears to work as well as masked language modeling for NLP-related tasks. The literature around pre-training grows daily, but I think we've only really scratched the surface of potential pre-training methods. That's why I'm excited to see some new blood in NLP pre-training, which has been dominated by masked language modeling a la BERT.
That said, the paper involves some hackery that seems necessary to get the model to train. This includes the heuristics that are used to group documents into relevant batches to retrieve from (which is inherently non-differentiable) as well as others tricks like encouraging cross-lingual behavior via hardcoded overweighting of cross-lingual documents in the collected batches. These tricks act as a sort of "intelligent design" mechanism which is not uncommon in deep learning but does mean that the model is not entirely trainable end-to-end via gradient descent (though it mostly is).
Additionally, these steps are outlined in the paper but due to limitations of the human language are not easily replicable solely via the paper's explanation. The authors would need to open source the underlying model code for others to replicate and verify these results.
Model-specific training and architectural hacks aside, MARGE's performance is quite impressive and adds a new feather in the pre-training quiver for NLP models.
Join the Syndicate
Long-form essays on the economics of tech, with the data to back it up. All signal, no noise.
Read by 5,000+ founders, engineers, and investors.