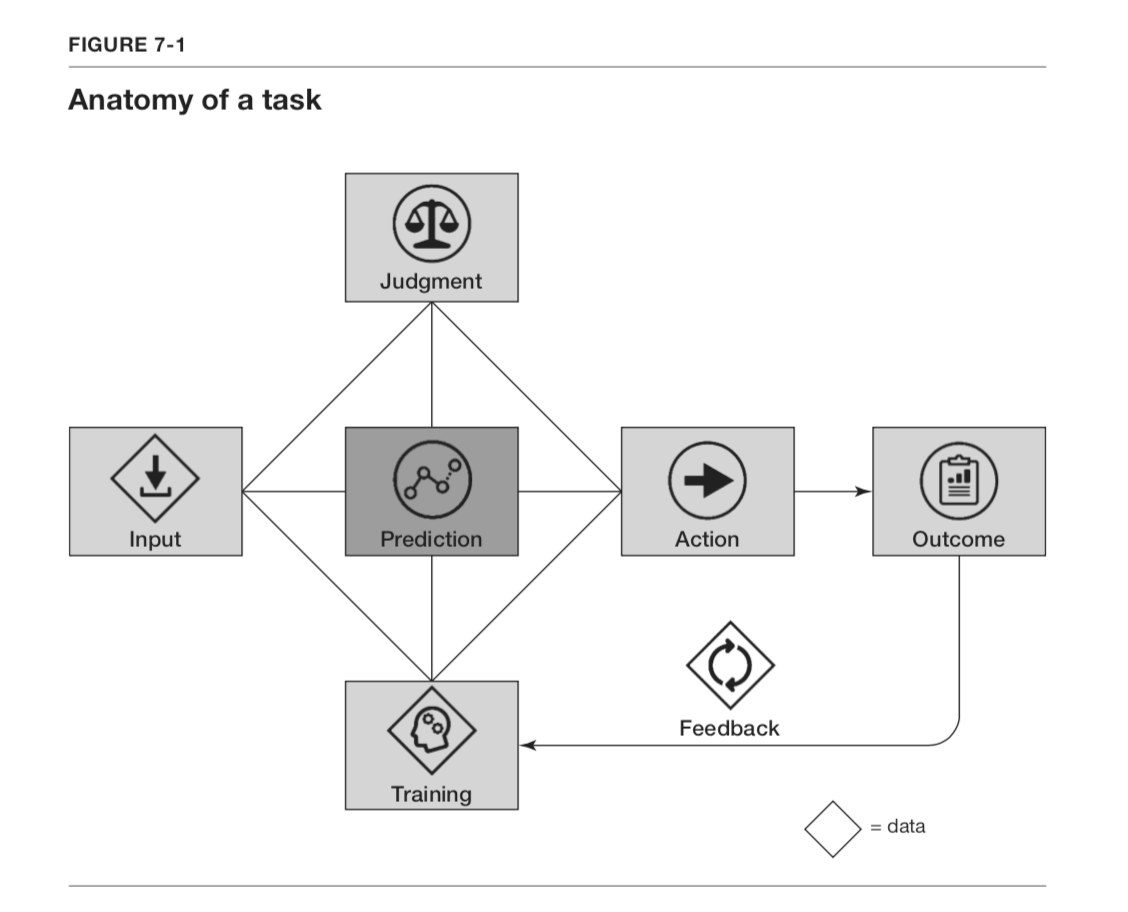
With the right representation, judgement is cheap
We can think about representation learning as the pre-training phase of model development whereas “judgement learning” corresponds to the fine-tuning phase.
It appears that pre-training of NLP models to achieve proper representations for words and sequences is more important to the the overall training regimen than fine-tuning on specific tasks. Learned representations are more important than what you do with them.
A tell-tale sign of mastery is increasingly complex chunks. These chunks enable higher-level thinking with a fixed amount of compute horsepower, as one only needs to reason about the higher-level chunks rather than the raw information. This reduces perceived complexity and compresses information.
- A beginner would see “a pawn here, a rook there”, and so on, a series of individual pieces. Masters, by contrast, saw much more elaborate “chunks”: combinations of pieces that they recognized as a unit, and were able to reason about at a higher level of abstraction than the individual pieces.
- Simon estimated chess masters learn between 25,000 and 100,000 of these chunks during their training, and that learning the chunks was a key element in becoming a first-rate chess player. Such players really see chess positions very differently from beginners.
Chunks are analogous to representations. Chunks are low-dimensional representations. Memorizing chunks is thus similar to learning representations.
Cal Newport considers Deep Work to be tasks that you couldn’t train a college-educated person to do in a short period of time. In this sense he relates necessary training time directly to the value of the work. If we think about training time as a “cost” then it could be said that learning good judgement (fine-tuning) is cheap relative to learning useful representations (pre-training). The most valuable work or training regimen should be that which is most costly in terms of training time. If we extend this to the machine learning context, learning representations is the “Deep Work” of machine learning, whereas learning judgement is relatively shallow work (once representations have been learned).
Transclude of Learned-representations-are-more-important-than-what-you-do-with-them#757870
The notion that judgement is cheap is corroborated by the architectures of pre-trained NLP models (BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding), which oftentimes only require a single layer or shallow feed forward network to turn the input representation into some required task output. This is often overlooked but in some ways is an amazing result — with the right representation, you need almost no additional computation to successfully complete a wide range of difficult tasks.
Our task-specific models are formed by incorporating BERT with one additional output layer, so a minimal number of parameters need to be learned from scratch. – BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
According to Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer, fine-tuning a model from scratch (which isn’t really fine-tuning) results in much worse performance than with pre-training before fine-tuning. Fine-tuning is thus only cheap when the model has learned the right representation first. Judgement is cheap when equipped with the right representation, otherwise it’s quite expensive.
Expanding this outside the machine learning context, this idea would imply that attempting to learn judgement directly from the data itself (yours or others’ experiences) without first pre-processing the data or “pre-training” yourself is inefficient and unlikely to work. Pre-train your representations before learning judgement. In doing so, be careful not to fool yourself into thinking something is valuable simply because it takes a long time.
Transclude of Pre-train-your-representations-before-learning-judgement#6bef51
This differs markedly from the main thesis of Prediction Machines, which is that machine learning models mainly concern themselves with prediction and that judgement remains within the domain of humans. The authors also predict that judgement will rise in value given its complementary with prediction.
- But if judgement is in fact cheap once you are good at generating representations, I’m not so sure that humans will remain valuable in this way.
- I could be misreading this though. Perhaps they don’t think of being able to generate Q&A answers as judgement but really prediction. There still needs to be a human in the loop to know what to do with those predictions and make decisions. I’m not sure about this.